3.3 - Rogue hexadecimal codes and word elongation
By Christian Ryan
November 26, 2021
Retrieving our data
This blog post is a continuation of the previous two (3.1 & 3.2) examining tweets about covid, downloaded using the rtweet package.
If you are coming to this blogpost cold, there is a quick way to get the data as we left it at the end of blogpost 3.2. I have saved the cleaned dataset in my package as london_2.
You can install the r4psych package, run library(r4psych) and then import the data with the data(london_2) command. I rename my dataset to df, so I would advise doing this too. Here is a summary of the commands needed.
library(devtools)
install_github("Christian-Ryan/r4psych")
library(r4psych)
data(london_2)
df <- london_2
rm(london_2)
Here is a quick list of the text cleaning measures we have carried out so far:
- replaced emojis
- undone contractions
- deleted smart quotes
- deleted tags ‘@’
- deleted URLs
- deleted hashtags #
- replaced
& - replaced non-breaking spaces
- deleted EN-dashs
- reinstated ellipses
Let’s reload the main packages we have been using to process this dataset: the tidyverse collection and textclean packages.
library(tidyverse)
library(textclean)
We could take a look at a few tweets to get a sense of what is left to be tidied up, as we did in the previous posts, or we could try using a more active search strategy - for instance we could start by searching for more hexadecimal codes.
Generic hexadecimal search strategy
Let’s see if we can create a generic hexadecimal search strategy. We know that hexadecimal codes are some combination of number and letters between a group of angular bracket <>. For instance, you may recall that one of the simplest hexadecimal codes we came across in the last blogpost was for the non-breaking space, which was <c2><a0>. We can see if we can capture all the hexadecimal codes based on the simplest search pattern possible.
We can start by creating a dataframe with one string variable and see if we get a match to a couple of elements that contain different hexadecimal codes.
test_string <- tibble(text = c("this is some text with a hexadecimal code in it <c2><a0>",
"string without a code",
"some random words",
"the ellipsis is <e2><80><a6>",
"the last element"))
test_string
## # A tibble: 5 × 1
## text
## <chr>
## 1 this is some text with a hexadecimal code in it <c2><a0>
## 2 string without a code
## 3 some random words
## 4 the ellipsis is <e2><80><a6>
## 5 the last element
The simplest pattern matching would be to use a filter() function with a str_detect() and assign the pattern to be an opening angular bracket <. Let us see if this is sufficient.
test_string %>%
filter(str_detect(text, pattern = "<"))
## # A tibble: 2 × 1
## text
## <chr>
## 1 this is some text with a hexadecimal code in it <c2><a0>
## 2 the ellipsis is <e2><80><a6>
Indeed, this works rather well to pick out our two strings with hexadecimal codes in them. We can apply this to our real dataframe df and see what results we get. As our real dataframe has ninety variables, we will add a pull() function, to just capture the text of the tweets that contain hexadecimal codes.
df %>%
filter(str_detect(text, pattern = "<")) %>%
pull(text)
## [1] " I hope the programme gets properly noticed. Seems to be<f0><9f><a4><9e>Must have been a horrific experience for you with insight into what would inevitably happen as a consequence When I visited the Covid Memorial wall I thought how apt right opposite Parliament as a constant reminder!"
## [2] "Here's what you need to know as travelling (hopefully) gets easier! airplane <ef><b8><8f> vertical traffic light "
## [3] " I am Neil do not get me started on the kids <f0><9f><a4><a3> We all need to stand together. Have a great weekend."
## [4] "This winter, the NHS will be providing COVID-19 booster vaccines to certain groups The booster jabs will start being offered from 22 September and more information on booking will be available soon Read more right arrow <ef><b8><8f> "
## [5] "The helps us to keep enjoying the thing we love microphone <f0><9f><a5><b3><f0><9f><8f><96><ef><b8><8f> Book yours now backhand index pointing right "
Here we see the 5 tweets that are left with 5 hexadecimal codes in them, some of which appear more than once. The codes are:
<ef><b8><8f>
<f0><9f><8f><96>
<f0><9f><a4><a3>
<f0><9f><a4><9e>
<f0><9f><a5><b3>
<ef><b8><8f>
This first one is a little different to the others in this list, in that it is a control emoji rather than being a character in its own right. It is a variation selector that can change the way the preceding character is rendered. In this case, we can see that the preceding character in the second tweet above was airplane and in the fourth tweet was right arrow. We can safely delete both of these instances of <ef><b8><8f> as not being informative for our text analysis. We can use the same strategy as in the last blog post - using an mgsub() function. We can check this works, by using a filter including the phrase “vertical traffic light” that we know occurs in the second tweet above.
df %>%
filter(str_detect(text, pattern = "vertical traffic light")) %>%
mutate(text = mgsub(text, pattern = "<ef><b8><8f>",
replacement = "")) %>%
pull(text)
## [1] "Here's what you need to know as travelling (hopefully) gets easier! airplane vertical traffic light "
That has worked, so let’s apply it to the whole dataframe.
df <- df %>%
mutate(text = mgsub(text, pattern = "<ef><b8><8f>",
replacement = ""))
<f0><9f><8f><96> etc.
Our next four hexadecimal codes, that appear in the three remaining tweets, all represent emojis. For instance, the next code in our list is <f0><9f><8f><96> which is the code for BEACH WITH UMBRELLA 🏖 and we might ask why wasn’t this emoji identified and replaced by the replace_emoji() function we used earlier. It could be that it simply isn’t in the word-list for this function. We can have a look at the word-list, which is inherited from another package (the lexicon package), by loading the package and running the data() function on the hash_emojis dataframe. It copies the table of emojis and their hexadecimal codes to our environment.
library(lexicon)
data(hash_emojis)
hash_emojis
## x y
## 1: <e2><86><95> up-down arrow
## 2: <e2><86><99> down-left arrow
## 3: <e2><86><a9> right arrow curving left
## 4: <e2><86><aa> left arrow curving right
## 5: <e2><8c><9a> watch
## ---
## 730: <f0><9f><9a><bc> baby symbol
## 731: <f0><9f><9a><bd> toilet
## 732: <f0><9f><9a><be> water closet
## 733: <f0><9f><9a><bf> shower
## 734: <f0><9f><9b><80> person taking bath
We can run a quick check on the word “umbrella” to see if BEACH WITH UMBRELLA appears in the list. We don’t need to worry about capitalisation as all of the y variable text descriptions of the emojis are in lower-case.
hash_emojis %>%
filter(str_detect(y, pattern = "umbrella"))
## x y
## 1: <e2><98><82> umbrella
## 2: <e2><98><94> umbrella with rain drops
## 3: <f0><9f><8c><82> closed umbrella
Though the list contains three emojis with umbrellas, it seems that BEACH WITH UMBRELLA isn’t included in the word-list supplied by the lexicon package.
Customising the lexicon
If we carried out this same process of searching for each of the four codes, we would establish that the reason our four hexadecimal codes for emojis were not replaced by the replace_emoji() function was that they were missing from the lexicon. We could use mgsub() to manually replace each one, and that would be relatively straightforward, but a better strategy is to add these emojis to the lexicon and then re-run our replace_emoji() function. The benefit of this approach is that if we need to run the function again for some reason, or we want to run it on another dataset, we already have the lexicon with the updated list of emojis.
To customise the lexicon, we need to add the codes for our four missing emojis. I looked each of them up on this website:
Here are the codes and their text equivalents:
<f0><9f><8f><96> “beach with umbrella”
<f0><9f><a4><a3> “rolling on the floor laughing”
<f0><9f><a4><9e> “hand with index and middle fingers crossed”
<f0><9f><a5><b3> “face with party horn and party hat”
Creating a custom_emoji dataframe
Now we have a list of unrecognised hexadecimal codes and their text equivalents. We can create a very small dataframe with the same variable names (x and y) as the hash_emojis dataframe.
custom_emoji <- tibble(
x = c("<f0><9f><8f><96>",
"<f0><9f><a4><a3>",
"<f0><9f><a4><9e>",
"<f0><9f><a5><b3>"),
y = c("beach with umbrella",
"rolling on the floor laughing",
"hand with index and middle fingers crossed",
"face with party horn and party hat"))
We can add these custom emoji listings to the hash_emojis dataset with a bind_rows() function, which will append our four new lines to the end of the dataframe. We can run tail() on the updated hash_emojis dataframe to check this has worked.
hash_emojis <- bind_rows(hash_emojis, custom_emoji)
tail(hash_emojis)
## x y
## 1: <f0><9f><9a><bf> shower
## 2: <f0><9f><9b><80> person taking bath
## 3: <f0><9f><8f><96> beach with umbrella
## 4: <f0><9f><a4><a3> rolling on the floor laughing
## 5: <f0><9f><a4><9e> hand with index and middle fingers crossed
## 6: <f0><9f><a5><b3> face with party horn and party hat
Before we re-run our replace_emoji() function on df, we need a way to track the three tweets we identified as containing hexadecimal codes. We can do this by utilising the tweet status_url that we saw in the last blogpost, which is a unique tweet identifier.
Capture tweet status_url with hex codes present
We can run the same filter as before, matching the pattern "<", use the pull() function to take out just the status_url codes, and save these to a character vector that we will call “tweets_with_hex”.
tweets_with_hex <- df %>%
filter(str_detect(text, pattern = "<")) %>%
pull(status_url)
Using the customised hash_emojis dataset
Next, we will re-run our replace_emoji() function, but this time with our hash_emoji dataframe that we updated with four custom hexadecimal code/text pairs. We can then filter by the status_url argument, using the %in% operator, which allows us to specify which tweets to include - we will just include those where the status_url code matches an entry in our tweets_with_hex character vector. Finally, we pull() the text variable.
df %>%
mutate(text = replace_emoji(text, emoji_dt = hash_emojis)) %>%
filter(status_url %in% tweets_with_hex) %>%
pull(text)
## [1] " I hope the programme gets properly noticed. Seems to be hand with index and middle fingers crossed Must have been a horrific experience for you with insight into what would inevitably happen as a consequence When I visited the Covid Memorial wall I thought how apt right opposite Parliament as a constant reminder!"
## [2] " I am Neil do not get me started on the kids rolling on the floor laughing We all need to stand together. Have a great weekend."
## [3] "The helps us to keep enjoying the thing we love microphone face with party horn and party hat beach with umbrella Book yours now backhand index pointing right "
We can see the final three tweets that had contained rogue hexadecimal codes, now contain appropriate text equivalents instead. We need to run this same chunk without the filter() and pull() functions and reassign it back to our df to make the changes permanent.
df <- df %>%
mutate(text = replace_emoji(text, emoji_dt = hash_emojis))
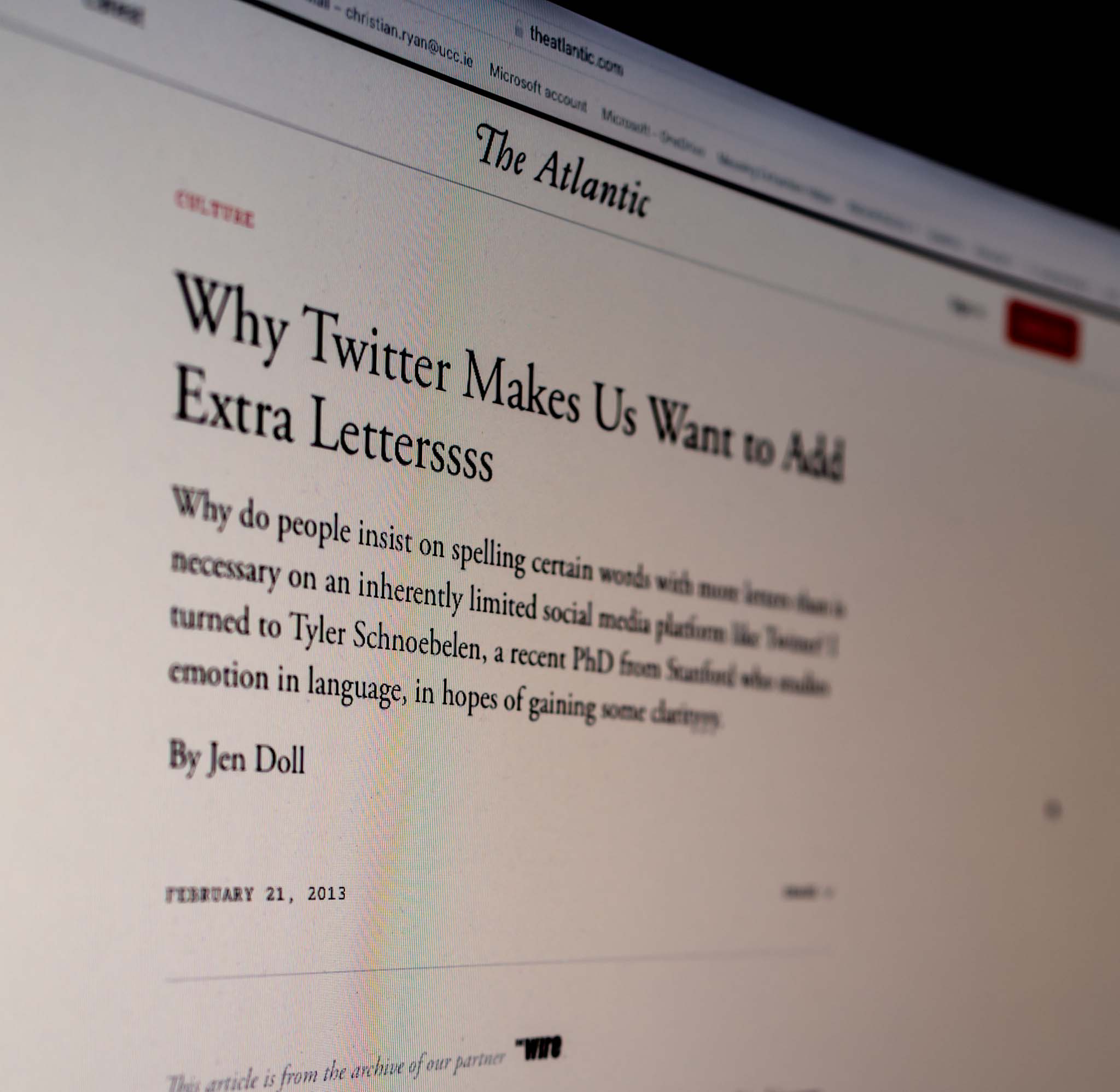
Word elongation
After carrying out the latest text replacements, I used the slice() and pull() combination we saw in the last post to scroll through the text of each of the tweets in batches of 10, to see if any other quirks of twitter usage remain. Tweet 45 is interesting.
df %>%
slice(45) %>%
pull(text)
## [1] "Of course my test results say I have fucking covid and now I have to miss the finance away day and work from home instead for 10 days for fuckssssssssssssssss sakeeeeeeeeeee"
Notice the use of extra “s"s and “e"s for emphasis. This is known as ‘word elongation’, and lucky for us, textclean has a function to fix it! Let’s have a quick look at how it works. We can create a tiny character vector with one element, called long_word and print it to the console
long_word <- c("this is a way to add emphasissssssss")
long_word
## [1] "this is a way to add emphasissssssss"
Next, we will send it to the replace_word_elongation() function from the textclean package.
replace_word_elongation(long_word)
## [1] "this is a way to add emphasis"
It worked perfectly on this word. We can try it on tweet 45.
df %>%
slice(45) %>%
mutate(text = replace_word_elongation(text)) %>%
pull(text)
## [1] "Of course my test results say I have fucking covid and now I have to miss the finance away day and work from home instead for 10 days for fucks sake"
Likewise, it worked perfectly with our real-world sample. So we can apply it to the dataframe df.
df <- df %>%
mutate(text = replace_word_elongation(text))
Summary
We have taken a couple more steps to clean up our tweet collection. We replaced orphan hexadecimal codes by using a customised hash_emojis dataset and we have removed word elongation. We could have used other text cleaning packages to clean the tweets (in R, there are always multiple ways to do anything), and some of them would have automated elements of this process. However, one of the benefits of textclean package is that you can clean up the tweets independently of the tokenisation process. This allows the user to read the tweets in their cleaned state, before moving to the bag-of-words approach. If one wanted to do some close-reading, thematic analysis or hermeneutic work to supplement the bag-of-words method, this is advantageous. In the next post we can carry out a tokenisation and begin to explore the sentiment content of tweets about covid. To summarise our steps, the chunk below shows all of the steps we have taken in the past 3 posts.
df <- df %>%
mutate(text = replace_tag(text, pattern = "(?<![@\\w])@([A-Za-z0-9_]+)\\b"), # tags
text = replace_url(text), # urls
text = replace_hash(text), # hashtags
text = mgsub(text, pattern = "&", replacement = "and"), # &
text = mgsub(text, pattern = "<c2><a0>", replacement = " "), # non-breaking space
text = mgsub(text, pattern = "<e2><80><93>", replacement = ""), # EN dash
text = mgsub(text, pattern = "<e2><80><a6>", replacement = "...")) # ellipsis
custom_emoji <- tibble(
x = c("<f0><9f><8f><96>",
"<f0><9f><a4><a3>",
"<f0><9f><a4><9e>",
"<f0><9f><a5><b3>"),
y = c("beach with umbrella",
"rolling on the floor laughing",
"hand with index and middle fingers crossed",
"face with party horn and party hat")) # create custom emoji dataset
library(lexicon)
data(hash_emojis) # load hash_emoji dataset
hash_emojis <- bind_rows(hash_emojis, custom_emoji) # join custom set to hash_emoji
df <- df %>%
mutate(text = replace_emoji(text, emoji_dt = hash_emojis), # re-run with custom lexicon
text = replace_word_elongation(text)) # word elongation
- Posted on:
- November 26, 2021
- Length:
- 12 minute read, 2433 words
- See Also: