3.4 Variable trimming and twitter objects
By Christian Ryan
January 3, 2023
A quick explanation is in order as to why this blogpost is only just being posted now, despite having been written over a year ago. If you know me personally, you will already know the answer - and if you do not, let’s just say grief can mess with the best-laid plans.
Introduction
This blogpost is a continuation of the previous three on Twitter data, so as a preliminary step we will load the packages collection tidyverse and retrieve the cleaned data, which was saved as london_3.Rdata. As ever, if you haven’t followed the previous steps, you can still load the dataset from my package r4psych and, if you need to, rename it df.
library(tidyverse)
library(r4psych)
data("london_3")
df <- london_3
rm(london_3)
In this blogpost, we are going to be tokenising our tweets. This results in a much longer dataframe, so it would be prudent to slim down the data before we do this - we want to delete any irrelevant variables that we are not likely to want to include in any future analysis. Sometimes this process can be very simple, for instance, if we have designed the study and already know what each variable represents. But with ‘found data’ such as that pulled from Twitter, it is a little more tricky. If like me, you don’t know what all the variable names mean yet, it can be helpful to delete a few at a time, while working through the data, figuring out what each variable represents. Either way, we work through the dataset, deciding which variables to keep or delete, and use select() functions to carry out the changes. A useful function for virtually turning the dataset on its side, so we can read down the variable names, is glimpse().
df %>%
glimpse()
## Rows: 100
## Columns: 90
## $ user_id <chr> "1886093119", "1886093119", "23231169", "13562…
## $ status_id <chr> "1439142765959467008", "1439142760422989826", …
## $ created_at <dttm> 2021-09-18 08:22:28, 2021-09-18 08:22:26, 202…
## $ screen_name <chr> "emeicen", "emeicen", "Jed_Die", "rosie_dodds"…
## $ text <chr> "Many more applied for EU citizenship on the b…
## $ source <chr> "Twitter Web App", "Twitter Web App", "Twitter…
## $ display_text_width <dbl> 277, 265, 252, 227, 270, 250, 175, 69, 120, 27…
## $ reply_to_status_id <chr> "1439142764327878656", NA, "143894377470558618…
## $ reply_to_user_id <chr> "1886093119", NA, "179544579", "25108214", "11…
## $ reply_to_screen_name <chr> "emeicen", NA, "ohsouthlondon", "leoniedelt", …
## $ is_quote <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALS…
## $ is_retweet <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALS…
## $ favorite_count <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0…
## $ retweet_count <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ quote_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ reply_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ hashtags <list> NA, NA, NA, NA, NA, NA, NA, NA, <"NHS", "covi…
## $ symbols <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ urls_url <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "…
## $ urls_t.co <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "…
## $ urls_expanded_url <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "…
## $ media_url <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "http…
## $ media_t.co <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "http…
## $ media_expanded_url <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "http…
## $ media_type <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "phot…
## $ ext_media_url <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "http…
## $ ext_media_t.co <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "http…
## $ ext_media_expanded_url <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "http…
## $ ext_media_type <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ mentions_user_id <list> NA, NA, <"179544579", "85307509">, "25108214"…
## $ mentions_screen_name <list> NA, NA, <"ohsouthlondon", "CPFC">, "leoniedel…
## $ lang <chr> "en", "en", "en", "en", "en", "en", "en", "en"…
## $ quoted_status_id <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_text <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_created_at <dttm> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ quoted_source <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_favorite_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_retweet_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_user_id <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_screen_name <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_name <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_followers_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_friends_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_statuses_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_location <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_description <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_verified <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_status_id <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_text <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_created_at <dttm> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ retweet_source <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_favorite_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_retweet_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_user_id <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_screen_name <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_name <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_followers_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_friends_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_statuses_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_location <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_description <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_verified <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ place_url <chr> NA, NA, NA, NA, NA, NA, NA, "https://api.twitt…
## $ place_name <chr> NA, NA, NA, NA, NA, NA, NA, "Hounslow", NA, NA…
## $ place_full_name <chr> NA, NA, NA, NA, NA, NA, NA, "Hounslow, London"…
## $ place_type <chr> NA, NA, NA, NA, NA, NA, NA, "city", NA, NA, NA…
## $ country <chr> NA, NA, NA, NA, NA, NA, NA, "United Kingdom", …
## $ country_code <chr> NA, NA, NA, NA, NA, NA, NA, "GB", NA, NA, NA, …
## $ geo_coords <list> <NA, NA>, <NA, NA>, <NA, NA>, <NA, NA>, <NA, …
## $ coords_coords <list> <NA, NA>, <NA, NA>, <NA, NA>, <NA, NA>, <NA, …
## $ bbox_coords <list> <NA, NA, NA, NA, NA, NA, NA, NA>, <NA, NA, NA…
## $ status_url <chr> "https://twitter.com/emeicen/status/1439142765…
## $ name <chr> "Monika Cenarska 💙💚3.5% #FBPA #FBPE #BLM #GT…
## $ location <chr> "London", "London", "South London", "South Eas…
## $ description <chr> "Teaching piano, loving it\n\nTruth hurts, lie…
## $ url <chr> NA, NA, NA, "https://t.co/KGe8Ufrv5h", "https:…
## $ protected <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALS…
## $ followers_count <int> 5223, 5223, 482, 251, 558, 119, 739, 33, 485, …
## $ friends_count <int> 5550, 5550, 159, 1670, 1222, 478, 1062, 186, 1…
## $ listed_count <int> 2, 2, 28, 0, 7, 5, 17, 1, 14, 14, 118, 18, 3, …
## $ statuses_count <int> 54349, 54349, 70554, 7026, 18730, 1093, 3739, …
## $ favourites_count <int> 75406, 75406, 44124, 6200, 63300, 1088, 3601, …
## $ account_created_at <dttm> 2013-09-20 10:14:19, 2013-09-20 10:14:19, 200…
## $ verified <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALS…
## $ profile_url <chr> NA, NA, NA, "https://t.co/KGe8Ufrv5h", "https:…
## $ profile_expanded_url <chr> NA, NA, NA, "http://rosieahoy.wordpress.com", …
## $ account_lang <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ profile_banner_url <chr> "https://pbs.twimg.com/profile_banners/1886093…
## $ profile_background_url <chr> "http://abs.twimg.com/images/themes/theme1/bg.…
## $ profile_image_url <chr> "http://pbs.twimg.com/profile_images/133638532…
Before we start to decipher these variables and make judgements about which to keep, we should note that Twitter calls tweets “status updates”. This is informative as some variables contain names with “status” embedded in them, which need to be read as “tweets”. For instance, one variable is called “statuses_count” - which is a count of how many tweets this particular account has sent.
According to the Twitter developer website, tweets contain root-level elements, such as status_update and
status_id, but they also contain other child objects such as user, which stores metadata about the user. We can see some of the user data toward the end of the variables - items such as followers_count and statuses_count refer to the user, rather than the tweet. Whereas, some of the variables earlier in the dataframe, such as status_id, created_at and text are all unique to this particular tweet.
As this is a large and unfamiliar dataset, it will be easier to prune the data in smaller steps, as we are not yet clear how the final dataset should look. The tidyverse has some helpful tools for this incremental approach, particularly when we want to delete multiple variables with similar prefixes.
Selecting variables by prefix
Let’s begin by deciding that we want to keep much of the information about the tweet itself and the user, but we don’t think we need any of the retweet information. The select() function from dplyr has a helper function starts_with() that allows us to pass a character string to the select() function to match with any variable that begins with these characters. We can use “retweet” and see what it pulls out.
df %>%
select(starts_with("retweet")) %>%
glimpse()
## Rows: 100
## Columns: 16
## $ retweet_count <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ retweet_status_id <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_text <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_created_at <dttm> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ retweet_source <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_favorite_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_retweet_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_user_id <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_screen_name <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_name <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_followers_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_friends_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_statuses_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_location <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_description <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ retweet_verified <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
We can see that it has identified 16 variables that begin with the word “retweet”. As we don’t want these we can now use the subtraction syntax with select() to get rid of them and overwrite the dataframe.
df <- df %>%
select(-starts_with("retweet"))
We want to eliminate all the variables that refer to quoting in our dataset, as these are references within tweets to other tweets, and to simplify our data, we will discard these as well. We can use the same strategy of select() and starts_with().
df %>%
select(starts_with("quote")) %>%
glimpse()
## Rows: 100
## Columns: 16
## $ quote_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_status_id <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_text <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_created_at <dttm> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ quoted_source <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_favorite_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_retweet_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_user_id <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_screen_name <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_name <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_followers_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_friends_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_statuses_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_location <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_description <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ quoted_verified <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
There are 16 variables that begin with “quote”, which we can deselect.
df <- df %>%
select(-starts_with("quote"))
Character vectors for selecting multiple variables
At this stage, it may be more efficient to make a small list of the starts_with characters that we wish to eliminate. This could include:
- account
- country
- display
- ext
- is
- lang
- media
- mention
- place
- profile
- protected
- reply
- source
- urls
- verified
We can put these phrases into a character vector, which we will call ‘prefixes’.
prefixes <- c("account", "country", "display", "ext", "lang",
"is", "media", "mention", "place", "protected",
"profile", "reply", "source", "url", "verified")
Now we can attempt to deselect variables based on their presence in our prefixes character vector. Initially, I imagined that we would be using the %in% syntax for this step, to specify that the variables we want to exclude are in our vector prefixes. However, with a little experimentation, it became obvious that this is unnecessary. We can simply pass a vector instead of a hard-coded value to the starts_with() function, and this works fine.
df %>%
select((starts_with(prefixes))) %>%
glimpse()
## Rows: 100
## Columns: 38
## $ account_created_at <dttm> 2013-09-20 10:14:19, 2013-09-20 10:14:19, 2009…
## $ account_lang <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ country <chr> NA, NA, NA, NA, NA, NA, NA, "United Kingdom", N…
## $ country_code <chr> NA, NA, NA, NA, NA, NA, NA, "GB", NA, NA, NA, N…
## $ display_text_width <dbl> 277, 265, 252, 227, 270, 250, 175, 69, 120, 278…
## $ ext_media_url <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "http:…
## $ ext_media_t.co <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "https…
## $ ext_media_expanded_url <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "https…
## $ ext_media_type <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ lang <chr> "en", "en", "en", "en", "en", "en", "en", "en",…
## $ is_quote <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE…
## $ is_retweet <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE…
## $ media_url <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "http:…
## $ media_t.co <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "https…
## $ media_expanded_url <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "https…
## $ media_type <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "photo…
## $ mentions_user_id <list> NA, NA, <"179544579", "85307509">, "25108214",…
## $ mentions_screen_name <list> NA, NA, <"ohsouthlondon", "CPFC">, "leoniedelt…
## $ place_url <chr> NA, NA, NA, NA, NA, NA, NA, "https://api.twitte…
## $ place_name <chr> NA, NA, NA, NA, NA, NA, NA, "Hounslow", NA, NA,…
## $ place_full_name <chr> NA, NA, NA, NA, NA, NA, NA, "Hounslow, London",…
## $ place_type <chr> NA, NA, NA, NA, NA, NA, NA, "city", NA, NA, NA,…
## $ protected <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE…
## $ profile_url <chr> NA, NA, NA, "https://t.co/KGe8Ufrv5h", "https:/…
## $ profile_expanded_url <chr> NA, NA, NA, "http://rosieahoy.wordpress.com", "…
## $ profile_banner_url <chr> "https://pbs.twimg.com/profile_banners/18860931…
## $ profile_background_url <chr> "http://abs.twimg.com/images/themes/theme1/bg.p…
## $ profile_image_url <chr> "http://pbs.twimg.com/profile_images/1336385326…
## $ reply_to_status_id <chr> "1439142764327878656", NA, "1438943774705586183…
## $ reply_to_user_id <chr> "1886093119", NA, "179544579", "25108214", "118…
## $ reply_to_screen_name <chr> "emeicen", NA, "ohsouthlondon", "leoniedelt", "…
## $ reply_count <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ source <chr> "Twitter Web App", "Twitter Web App", "Twitter …
## $ urls_url <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "b…
## $ urls_t.co <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "h…
## $ urls_expanded_url <list> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "h…
## $ url <chr> NA, NA, NA, "https://t.co/KGe8Ufrv5h", "https:/…
## $ verified <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE…
We can see from the glimpse() above that this will delete 38 variables from our dataset. We can over-write these results.
df <- df %>%
select((-starts_with(prefixes)))
Selecting variables by suffix
So far we have focused on variable prefixes. However, sometimes it is the suffix that defines a group of variables we wish to eliminate. For instance, our dataset contains three variables that end with “coords”. We don’t need these values so we can use the sister function to starts_with() - unsurprisingly called ends_with().
df %>%
select(ends_with("coords")) %>%
glimpse()
## Rows: 100
## Columns: 3
## $ geo_coords <list> <NA, NA>, <NA, NA>, <NA, NA>, <NA, NA>, <NA, NA>, <NA, …
## $ coords_coords <list> <NA, NA>, <NA, NA>, <NA, NA>, <NA, NA>, <NA, NA>, <NA, …
## $ bbox_coords <list> <NA, NA, NA, NA, NA, NA, NA, NA>, <NA, NA, NA, NA, NA, …
And we can overwrite this change to the dataset.
df <- df %>%
select(-ends_with("coords"))
User object
We have made good progress in slimming down the dataset with some decisions about where the focus should be, and the use of some select() and helper functions. There are still some variables that we may be curious about - for instance, what is the difference between a twitter “screen_name” and “name” values? We already have the user_id as a unique identifier for each twitter user, so two additional names as identifiers may not be required. Checking details on Twitter’s developer page reveals that the user_id is a unique identifier for each Twitter account and that it does not change. By contrast, both screen_name and name can be changed by the user. Another difference is that the name is typically capped at 50 characters, whereas the screen_name has a maximum of 15 characters. Let’s have quick look at a few users' name, screen_name and user_id.
df %>%
slice(1, 10, 12, 16) %>%
select(user_id, name, screen_name)
## # A tibble: 4 × 3
## user_id name screen_name
## <chr> <chr> <chr>
## 1 1886093119 Monika Cenarska 💙💚3.5% #FBPA #FBPE #BLM #GTTO emeicen
## 2 149592451 raw groove rawgroove
## 3 520720055 Nigeria Newspapers Online NigNewspapers
## 4 20224725 Cindy pheonixclb
I have selected a few particular users here to illustrate the variety of usage in these three identifiers. The first entry in our output shows that the name variable can contain contextual information about the user - here we have the hashtags for Follow Back Progressive Alliance and Follow Back Pro EU, as well as Black Lives Matter and Get The Torries Out. If one were to conduct a political analysis on Twitter, the hashtags embedded in the name variable could be very useful information. The second tweet in the list above shows that some users almost replicated the name and screen_name variable (e.g. “raw groove” and “rawgroove”), with a tendency for the screen_name to contain no whitespace.
Detect whitespace
We could check to see if any of the screen_name entries contain whitespace, by using pull() function to convert the screen_name variable to a vector and passing this to our str_detect() function. We can use the pattern "[:space:]" to represent whitespace characters. This will return a logical vector which indicates whether or not each instance of screen_name contains whitespace.
df %>%
pull(screen_name) %>%
str_detect(pattern = "[:space:]")
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [13] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [25] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [37] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [49] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [61] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [73] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [85] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [97] FALSE FALSE FALSE FALSE
We can tell from all the “FALSE” values that none of the values in the screen_name variable in our small dataset contains whitespace.
To take a closer look at the format of the screen_name, we can just pull that variable.
df %>%
pull(screen_name)
## [1] "emeicen" "emeicen" "Jed_Die" "rosie_dodds"
## [5] "stphnfllws" "SamPlayle" "sacha_mbe" "BarnabyJames"
## [9] "rawgroove" "rawgroove" "biedexmarkets" "NigNewspapers"
## [13] "drsomiigbene" "the_majalla" "NellFrizzell" "pheonixclb"
## [17] "KayWierba" "nonewthing" "PeteGasLondon1" "PaulBuc31614268"
## [21] "Bexb47" "CapitalLONnews" "CapitalLONnews" "HeartLondonNews"
## [25] "HeartLondonNews" "MasterfulCrypto" "steffiec91" "guardianworld"
## [29] "TheDanRobinson" "profaxe" "ItsKateMcB" "sissibgn"
## [33] "WinnerStaysOn" "angelneptustar" "angelneptustar" "pressgazette"
## [37] "SeanOMalley29" "RIChessforlife" "jslinville" "Richard88523572"
## [41] "Robotmeile" "standardnews" "Wayne_A_J" "Independent"
## [45] "LostTeeshirt" "MarkWil56852709" "godfreyogle" "PM_Results"
## [49] "HWBarnet" "gamermohan" "Dorothy737" "Dorothy737"
## [53] "Dorothy737" "bbchealth" "JeremyAndrew11" "ThomasELyons2"
## [57] "Eritrea_EMN" "Eritrea_EMN" "rN4RzE82xSSg0lT" "IndiaAgnstLEFT"
## [61] "M33ARY" "Foggs101" "R0BERTJ0NES1" "UKtraveljourno"
## [65] "TomNullpointer" "Bruce_Ak" "prernabindra" "RashmiWriting"
## [69] "MuseumofLondon" "sheilaharg" "Telegraph" "MarkHaw73493633"
## [73] "LornaBaker1" "LornaBaker1" "Ronniemarkets" "emretezel"
## [77] "TeamTom10" "Al41181646" "LongCovidHell" "PStorkey"
## [81] "TracyAustin_" "David_T_Evans" "JulesCracknell" "KirstyRushbrook"
## [85] "Zubhaque" "BDifficile" "eurojournalENG" "fhussain73"
## [89] "anne123456781" "lewishamparish" "tom_the_bomb__" "WestMidHospital"
## [93] "nhssutton_" "NHSSouthwarkCCG" "policyatkings" "peaceandprotect"
## [97] "newmotionlabs" "wav_ey" "nhswandsworth_" "Toshk"
Notice they can contain capital letters, digits and underscores. It is quite helpful to see all the entries for one variable, to get a sense of the spread of values used, but it does produce quite long outputs. Let’s do the same for the name variable, but limit the number of values returned to 50. This time we will include one extra step - we can see in the list above that some of the names are repeated (“emeicen” is the author of the first and second tweets in the dataset). So this time we will use the unique() function that returns unique values only in a vector.
df %>%
select(name) %>%
unique() %>%
slice(1:50) %>%
pull()
## [1] "Monika Cenarska 💙💚3.5% #FBPA #FBPE #BLM #GTTO"
## [2] "Jed_Die"
## [3] "Rosie Dodds"
## [4] "STPHN 🌿"
## [5] "Sam Playle"
## [6] "Sacha Corcoran MBE #AntiRacist"
## [7] "BJHT"
## [8] "raw groove"
## [9] "Biedex Markets"
## [10] "Nigeria Newspapers Online"
## [11] "Dr Somi Igbene"
## [12] "MAJALLA"
## [13] "Nell Frizzell"
## [14] "Cindy"
## [15] "KayWierba"
## [16] "AI"
## [17] "PeteGasLondon #IAmJeremyCorbyn"
## [18] "Danceswithlooneys"
## [19] "Rebecca brown"
## [20] "Capital London News"
## [21] "Heart London News"
## [22] "Masterful Crypto"
## [23] "🌱steffiec91"
## [24] "Guardian World"
## [25] "Dan Robinson"
## [26] "professoraxeman"
## [27] "Kate McBride"
## [28] "𝑺𝒊𝒍𝒗𝒊𝒂 ✨fully vaxed & ready to stay home 💉✨"
## [29] "Winner Stays On September 18th"
## [30] "angie"
## [31] "Press Gazette"
## [32] "Sean O'Malley"
## [33] "R I"
## [34] "James Scott Linville"
## [35] "Richard"
## [36] "Mel 🕷"
## [37] "Evening Standard"
## [38] "Wayne"
## [39] "The Independent"
## [40] "T ⁷ she/her"
## [41] "Mark Williams"
## [42] "Godfreyogle"
## [43] "Gren Gale at PM Results"
## [44] "Healthwatch Barnet"
## [45] "Binu Mohan"
## [46] "Dorothy Cohen"
## [47] "BBC Health News"
## [48] "Andrew Broadbent"
## [49] "Thomas Lyons"
## [50] "ERITREAN MEDIA NETWORK"
It turns out there is a wealth of information stored in the name variable, above and beyond identifiers. Notice too, that they can contain far more than just text characters - we see hashtags, emojis, emoticons and even some font specifications. Some of the names are very informative, such as “Evening Standard” and “BBC Health News”, but we might want to check the authenticity of the account names in cases such as these. We have established that the user object contains some useful data that we wouldn’t want to lose, so we will keep the variables user_id, name and screen_name.
Entities objects
Looking down the list of the 17 variables we have left, symbols is notable for what appear to be lots of NA values. The symbols variable is part of the entities object within the tweet. Here is a quote from the twitter developer website that explains a bit more about what they are:
Entities provide metadata and additional contextual information about content posted on Twitter. The entities section provides arrays of common things included in Tweets: hashtags, user mentions, links, stock tickers (symbols), Twitter polls, and attached media.
https://developer.twitter.com/en/docs/twitter-api/v1/data-dictionary/object-model/entities
So the symbols refer to symbols for stock tickers. As these are not relevant to the current analysis we will delete them.
df <- df %>%
select(-symbols)
We may have done as much data trimming as possible for now, but before we move on, let’s take a quick look at one more variable - description - one of the user variables.
df %>%
slice(1, 4, 6) %>%
select(description) %>%
pull()
## [1] "Teaching piano, loving it\n\nTruth hurts, lies kill\nLove revives, forgiveness heals\n\nGreen socialist\n#UBI\n#Rejoin\n#BrexitIsaFascistCoup\n#SeriouslyAnnoying\nShe/her"
## [2] "Oxford season ticket holder. South Stand Lower. proud Auntie to 4 adorable children. Love travelling."
## [3] "Data Scientist at Kaizen Reporting, and Theoretical Physicist."
We can see that this variable stores substantial contextual data for the twitter user, and we may want to come back to this during our analysis.
Tidytext
We are going to tokenise our text data with tools from the tidytext package.
library(tidytext)
We can unnest our tokens or words so that each row represents an individual word from the tweet. In the process, all of the other data (user_id, name etc.) is replicated as appropriate. We will use the unnest_tokens() function from the tidytext package for this, in which we pass the name for our new variable to be created (“word”) and the name of the variable to be tokenised (“text”). We will move the word variable to the first column of the dataset with a select function.
df <- df %>%
unnest_tokens(word, text) %>%
select(word, everything())
Notice also, that as our dataset now has a row for each word, it has expanded from 100 rows (one per tweet) to 3306 rows (one per word). The unnest_tokens() function has converted each of the words to lowercase. The next common step in a linguistic analysis is to remove the stopwords (these are short function words such as “it”, “at”, “the”). We can do this with the anti_join() function.
df <- df %>%
anti_join(stop_words)
## Joining, by = "word"
I always find the syntax for this function rather obscure You might be wondering, how did anti-join() know to join by “word”? This is the choice we would want it to make, but we didn’t specify which variable in our df to match with variables in stop_words. Let’s take a quick peek at the stop_words dataframe.
data("stop_words")
head(stop_words)
## # A tibble: 6 × 2
## word lexicon
## <chr> <chr>
## 1 a SMART
## 2 a's SMART
## 3 able SMART
## 4 about SMART
## 5 above SMART
## 6 according SMART
We see that the stop_words dataframe only has two variables: the first of which is a variable called “word”. Recall that when we tokenized our text variable we renamed it as “word”. So when we apply the anti_join() function, it matches by any named vectors that the two dataframes have in common. Hence it finds, “word” in both dataframes and only keeps those that are not in both (this is why it is “anti”!). As a failsafe, we also get a message from the anti_join() letting us know which variable it joined by. If we had named our new variable something different when we tokenised, say we called it “tweet_word”, we would then need to be explicit with our “by =” argument.
df <- df %>%
unnest_tokens(tweet_word, text) %>%
anti_join(stop_words, by = c("tweet_word" = "word"))
Counting words
We have tokenised our words from the tweets and one of the very first tasks we might want to complete is to simply count the number of each unique word used. This will give us an insight into some of the themes that emerge in the tweets, before we go on to carry out a sentiment analysis. A simple way to do this is to use a ggplot to visualise the number of occurrences of each word. But if we are to use a visualisation, we need to have some awareness of how many words we are trying to display. We can use the unique() function that we have seen before - this returns all the unique entries in a vector. By wrapping it in the length() function, we can convert this vector into a count.
length(unique(df$word))
## [1] 874
So with 874 words to be represented on our y-axis, our graph will be rather long…!
To manage this we will include a filter() where we will filter out words that only appear a small number of times. I find that this is always a trial and error process - I started by filtering by 10 and found that it left only three words. Reducing this to 5, resulted in a graph of the top fourteen words - a much more informative visualisation. But there is no right answer here, and as we will see, you may want to change the filter number after we have done some more tidying on the dataset.
df %>%
count(word, sort = TRUE) %>%
filter(n > 5) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col() +
labs(y = NULL)
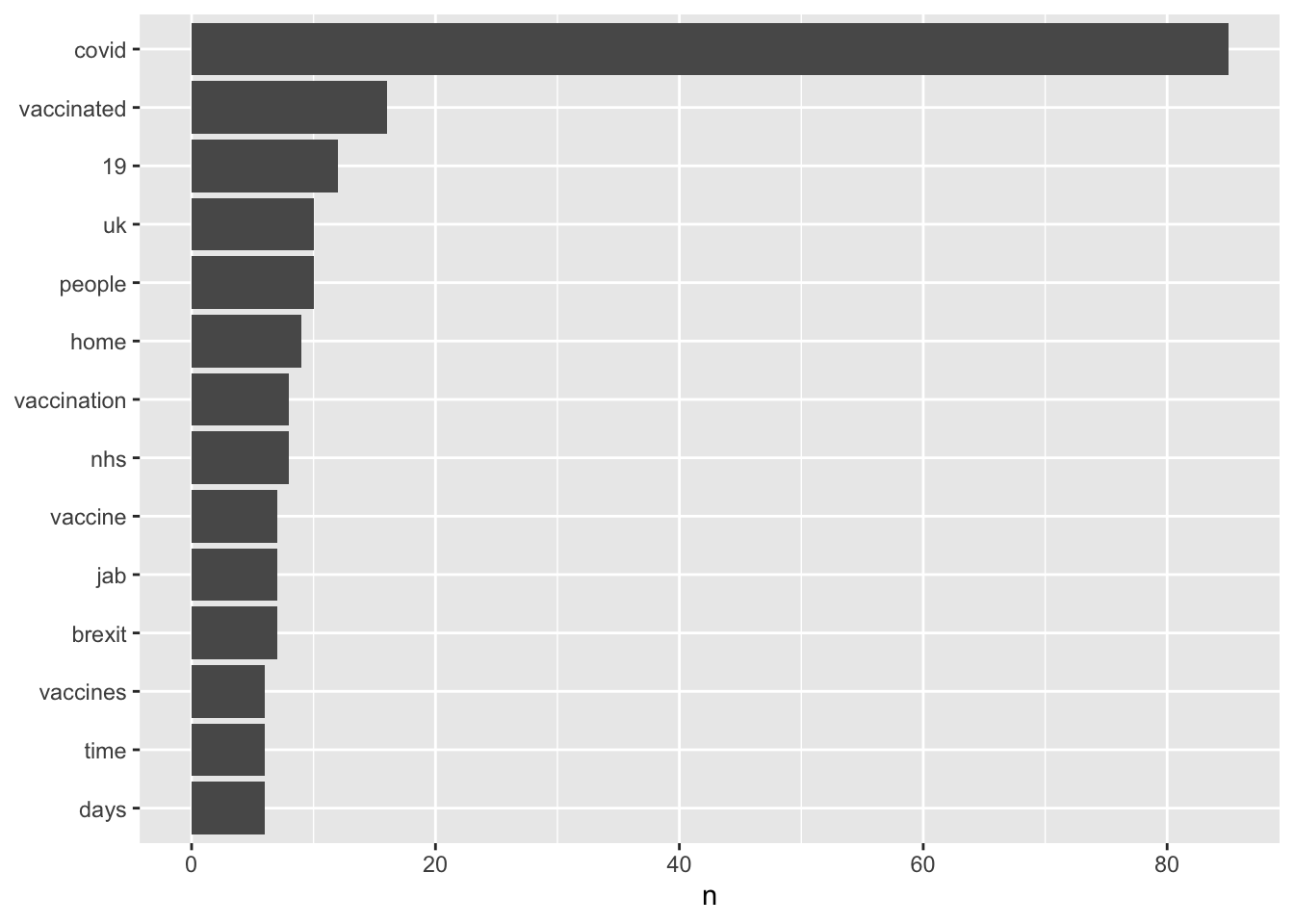
In the plot, we can see that we have some words that appear with very high frequency, but which are irrelevant, as they were part of our search terms in the twitter download - “covid”, “19”. We know that we are searching for tweets about covid-19, so any mention of these terms is not useful in helping us understand what people talk about when they are thinking about covid-19. So we can filter these out and re-run our count and plot.
df <- df %>%
filter(!str_detect(word, pattern = "covid")) %>%
filter(!str_detect(word, pattern = "19"))
As we are losing a couple of bars from the y-axis, we can also lower our count filter from 5 to 4.
df %>%
count(word, sort = TRUE) %>%
filter(n > 4) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col() +
labs(y = NULL)
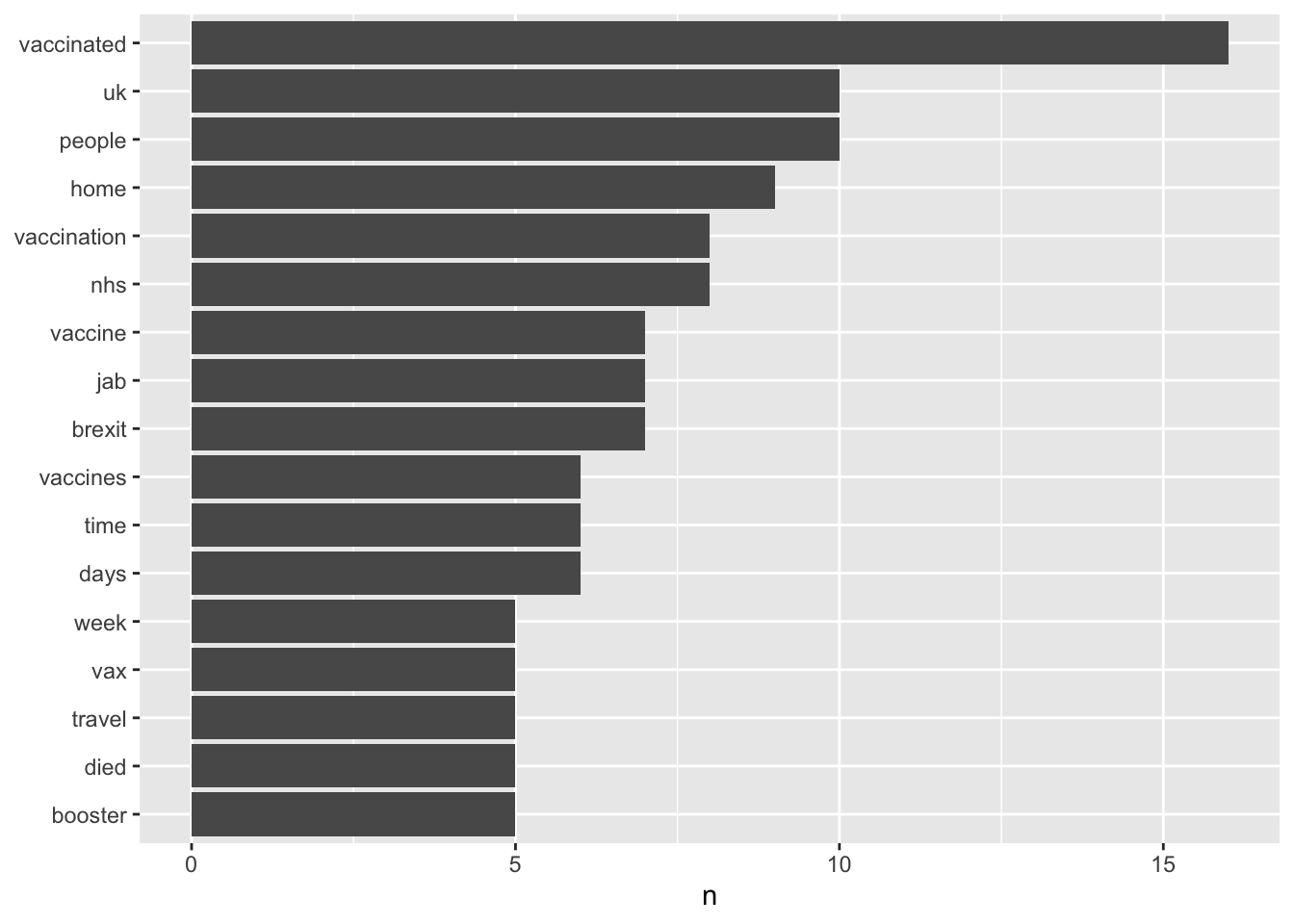
This gives us a better picture of the themes in our small London Twitter Covid-19 dataset. Keep in mind that the dataset is very small (only 100 tweets), even though, once we tokenise, the process results in a dataset of over a thousand rows. We can see in the graph how syntactic variations of words can be represented on different rows (vaccinated, vaccination, vaccine) even though we may regard them as semantically equivalent and prefer to count them as one word - one technique to address this is called word stemming, which we will look at later.
Conclusion
I have deliberately persisted with exploring this dataset, to demonstrate the functions for tidying and cleaning the data, before introducing a more substantial sample. In the next blogpost, I will introduce a sample of 500,000 tweets for us to work with, and we will begin some sentiment analysis. The pre-processing that has been demonstrated in each of the posts from 3.1 - 3.4 will have already been done, but I will save both the raw data and the processed data in my package r4psych in case you want to try the pre-processing steps yourself.
- Posted on:
- January 3, 2023
- Length:
- 27 minute read, 5607 words
- See Also: